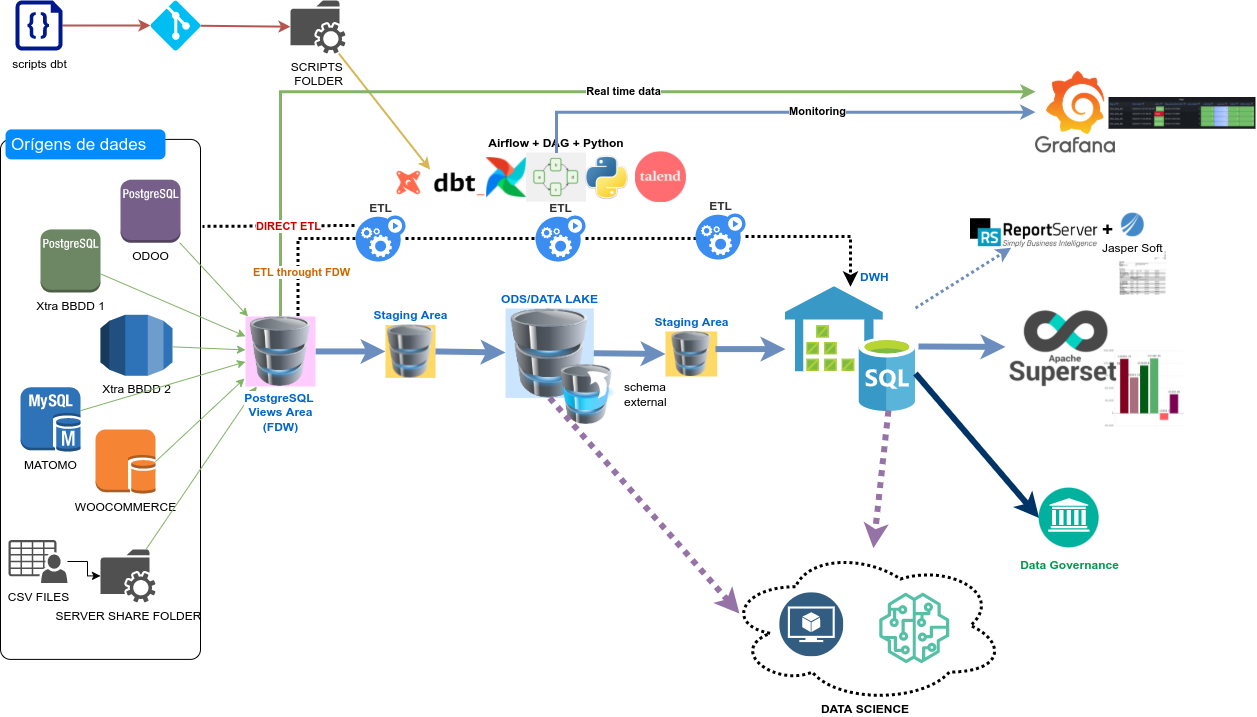
¶ Arquitectura Business Intelligence
Per tal d’adaptar-nos a les diferents mides de les organitzacions de l’economia social i solidària tenim diferents fases d’arquitectura. Totes elles estan pensades per poder suplir unes necessitats diferents en moments diferents del temps. La feina feta en qualsevol de les fases de les arquitectures és reutilitzable per a fases posteriors.
¶ Fase 0: Analítica interna des d’Odoo
Aquesta arquitectura està pensada per aquelles organitzacions que només volen explotar dades de l’Odoo i el volum de dades és relativament baix (<500.000 registres a les taules). És una arquitectura que no neceessita hardware nou i es basa en l’instal·lació de nous components d’Odoo i la configuració de consultes per a extreure les dades necessàries.
¶ Pros
- Ràpida d’implementar
- No necessita infrastructura extra
- Cost baix
¶ Contres
- Anaítica molt simple
- Només es poden consultar dades d’Odoo
- Perill de bloquejar l’ERP si es fan consultes molt grans
¶ Fase 1: Anàlisi de dades des dels operacionals
Aquesta arquitectura està pensada per aquelles organitzacions que tenen diversos orígens de dades (ex. Odoo, e-commerce, sistema de facturació, etc) i necessiten fer anàlisis creuats entre les diferents fonts de dades. El volum de dades és relativament baix, sobretot quan s’han de creuar dades de diferents orígens.
Aquesta arquitectura permet millorar el rendiment d’algunes consultes pesades mitjançant la persistència de dades amb dbt.
Aquesta arquitectura està basada en una base de dades Postgres amb el component Foreign Data Wrapper (FDW) que permet linkar les taules de diferents bases de dades i utilitzar-les conjuntament en una mateixa consulta. També hi ha un Airflow que serveix com a scheduler dels processos DBT. Un procés DBT no deixa de ser una consulta que pot configurar-se per ser total (càrrega de totes les dades) o incremental (càrrega de les dades noves). Amb l’Airflow es pot muntar un sistema d’alertes en cas que els processos falling a partir d’enviaments de missatges per e-mail. Com que els canals de Zulip tenen per darrera adreces de correu es poden configurar les alertes a través de Zulip. També es pot posar Grafana com a monitoring dels processos.
L’explotació de dades es fa amb Superset que es un visualitzador que permet la creació de Dashboards amb diferents tipus de visualitzacions gràfiques i el self-service per crear nous gràfics o amb ReportServer que és un portal per a l’execució d’informes més tradicionales (pdf, fulls de càlcul, etc.).
Tant Superset, com Airflow, com Grafana, com Report Server estan desplegats com a contenidors Docker. Aquesta arquitectura permet aixecar en un mateix servidor físic diverses instàncies d’aquests contenidors docker i, per tant, permet que diverses organitzacions comparteixin un mateix servidor per tal de reduir costos.
¶ Pros
- Ràpida d’implementar
- Flexible
- Cost baix
¶ Contres
- Rediment baix (depenent del volum de dades)
- Per defecte no es guarden dades històriques
- Perill de bloquejar els orígens de dades si es fan consultes molt grans

¶ Fase II: Creació de l’ODS històric
Aquesta fase està pensada com una evolució directa de l’anterior. Està pensada per organitzacions en que la fase I comença a tenir problemes de rendiment a causa del volumn de dades.
En aquesta fase s’afegeix una nova instància de Postgres per tal de fer una còpia de les dades de les bases de dades d’origen. Els informes que no calgui que siguin en temps real atacaran a aquesta nova base de dades, guanyant en rendiment i evitant bloquejos de les bases de dades d’origen.
L’explotació de dades es continua fent amb Superset o ReportServer.
A causa del volum de dades guardat no es recomana compartir servidor amb altes organitzacions.
¶ Pros
- Bloqueig de les fonts d’origen controlat
- Millor rendiment
- Flexible
- Es pot mantenir un registre de canvis dels orígens de dades
¶ Contres
- Cal implementar i mantenir processos per a la còpia de les dades d’origen
- Taules no orientades a consultes
- Cost més elevat
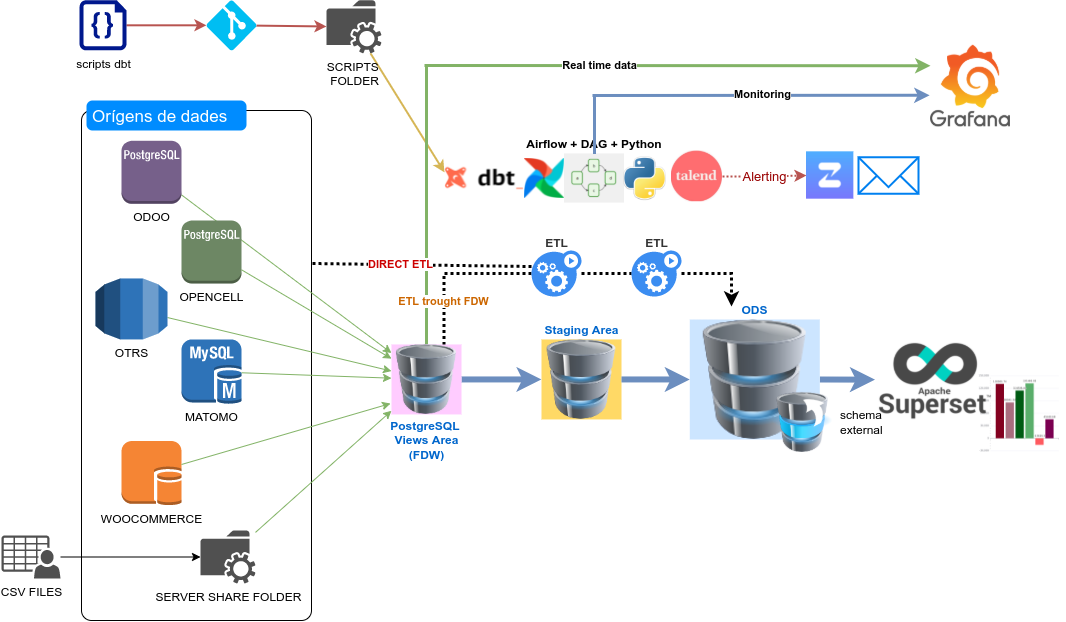
¶ Fase III: Creació del Datawharehouse
Aquesta fase està pensada per a organtizacions que ja tenen una maduresa en Business Intelligence i que tenen un volum de dades grans.
En aquesta fase s’afegeix una nova instància de Postgres on hi haurà el disseny del datawarehouse (DWH). El DWH permet crear estructures de dades orientades a consultes, fins i tot quan el volum de dades és molt gran. També facilita la implantació de processos de Data Governance per a millorar la capacitat de les usuàries d’explotar les dades de forma autònoma i per tenir control exhaustiu d’on provenen les dades. També facilita la integració amb algorismes de data science.
¶ Pros
- Bloqueig operacional controlat
- Disseny orientat a consultes i presa de decisions
- Molt bon rendiment en consultes
- Escalable amb el creixement de volum de dades
- Creació senzilla d’un diccionari de dades
¶ Contres
- Disseny més rígid
- Cal implementar i mantenir processos per a la còpia de les dades d’origen
- Cost més elevat